Learnersourcing
+ Crowdsourcing in Online Learning +
Time | April 2019 - May 2019
My role | Learner Experience Designer, Front-End Developer
◇
HIGHLIGHTS
Inspired by crowdsourcing, the idea of learnersourcing aims to leverage the enormous amount of learner-contributed data to fuel a better learning experience. In other words, everyone participating in the learning process is a co-creator of what they learn and how they learn it.
In this project, we targeted on exploring how learnersourcing can reform the traditional practice of multiple choice questions. We also discussed how data-driven modeling theories can be applied to improve learner-generated content.
◇
DEMONSTRATION
◇

How it works
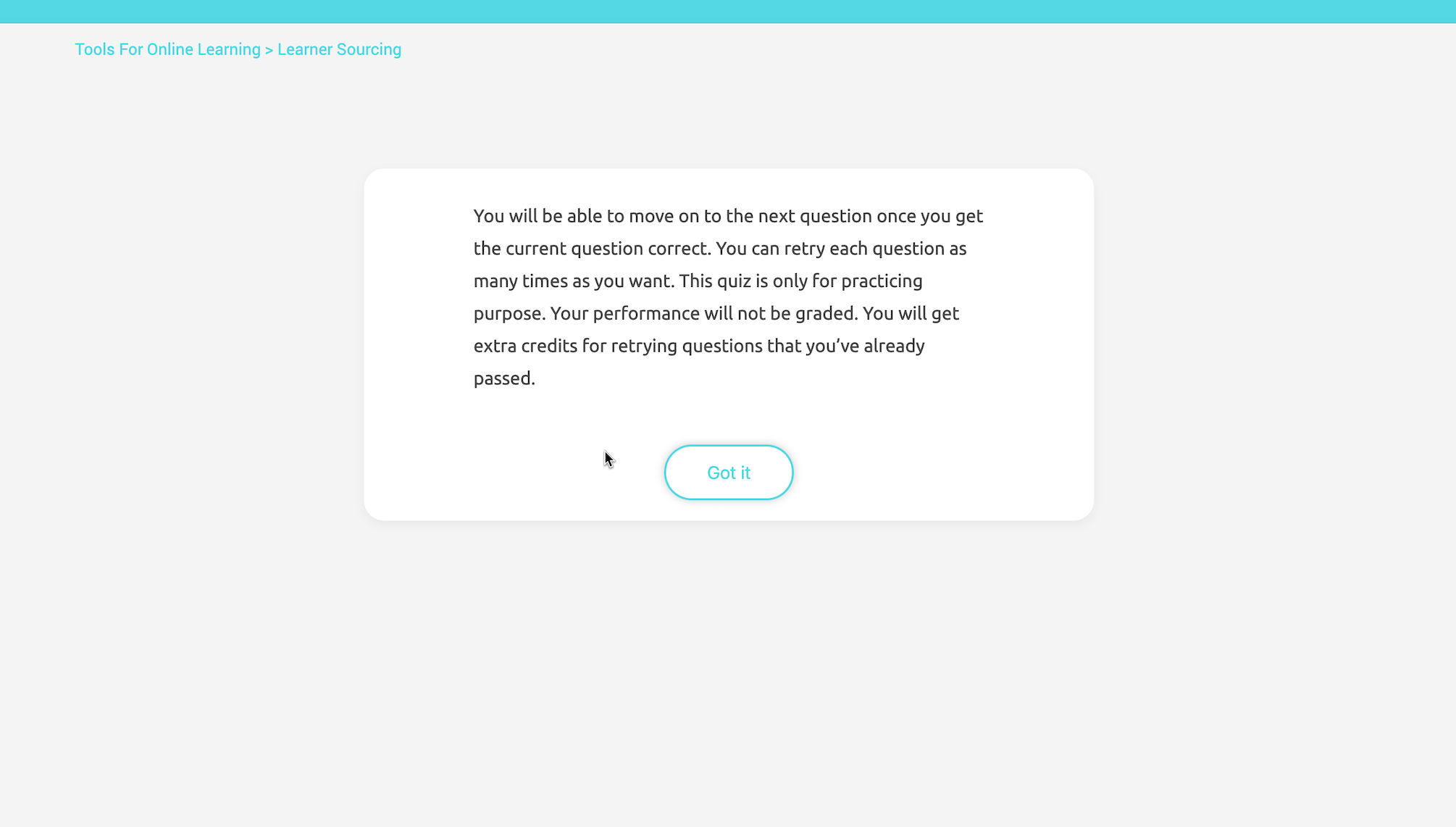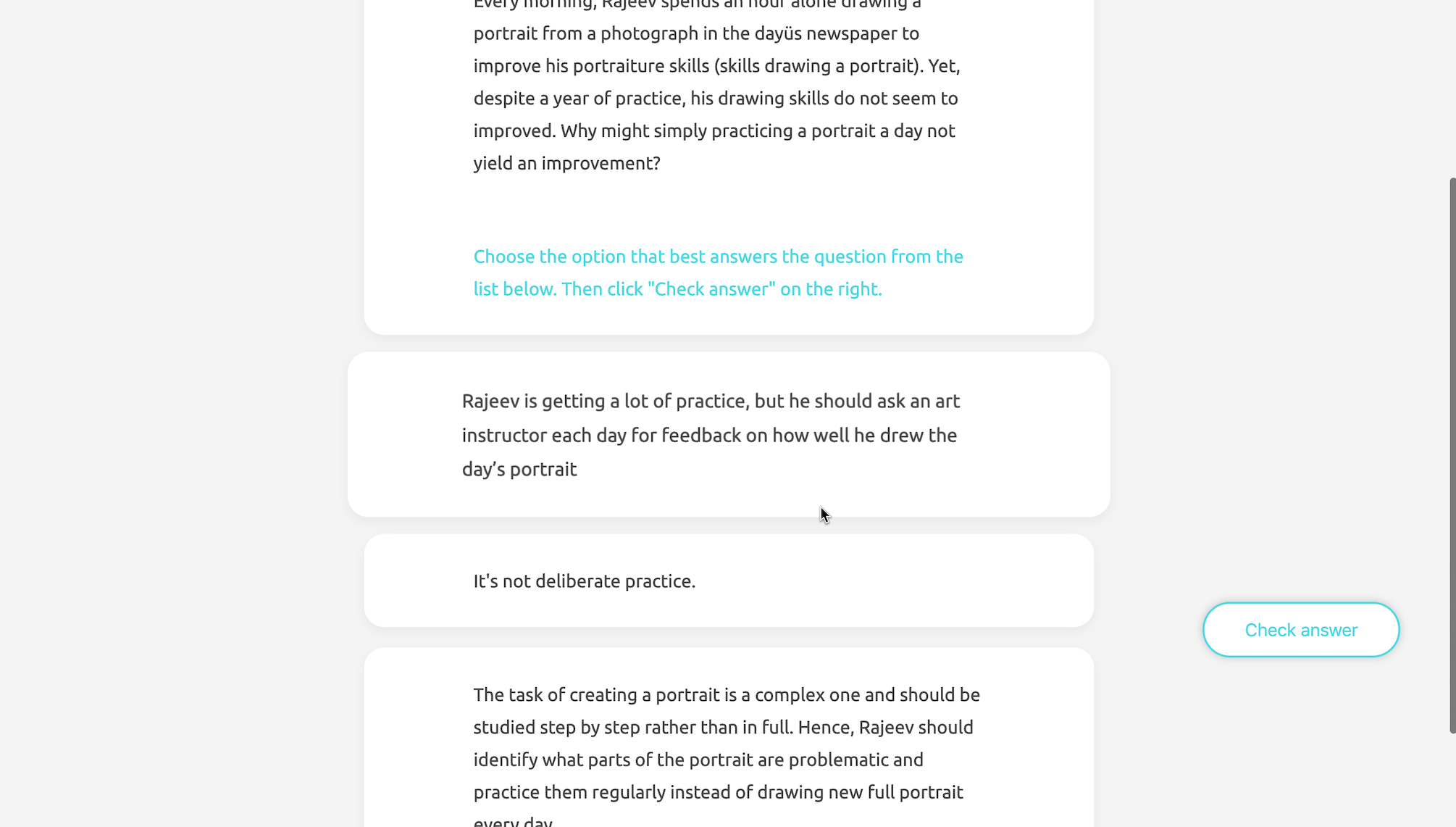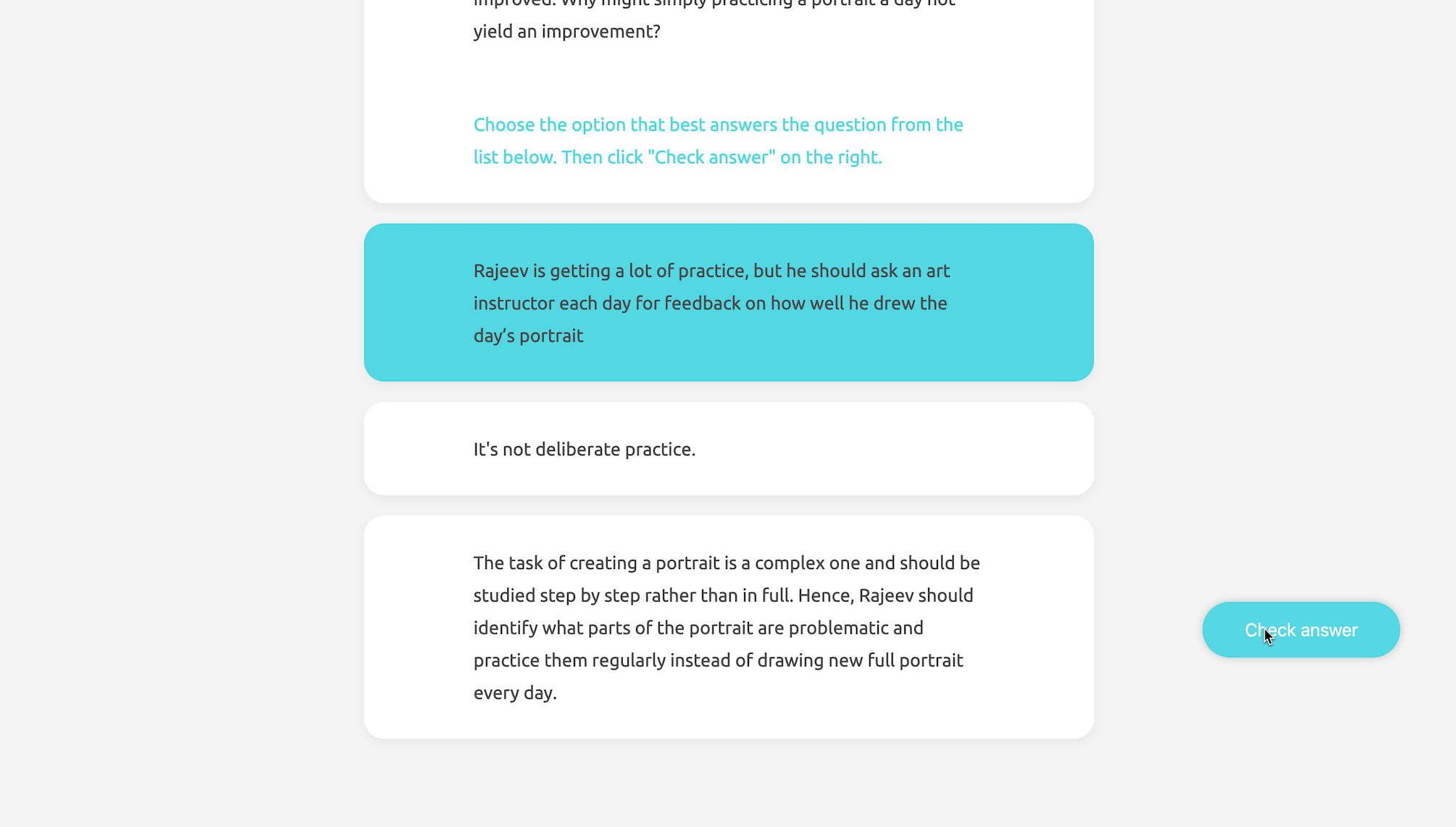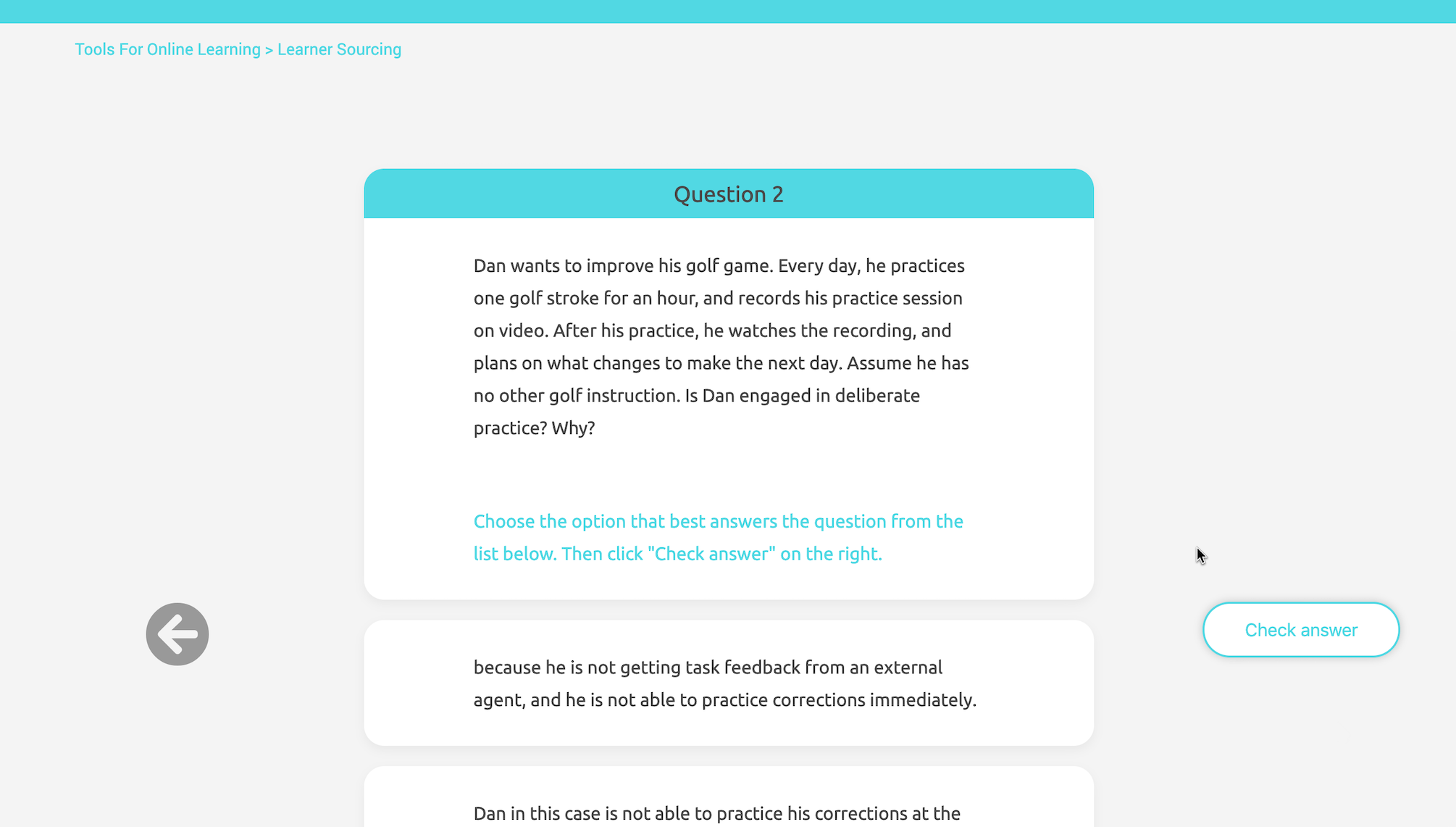
The basic idea of this project is to generate the options of multiple-choice questions with a set of precious learner responses from an open-ended question. In order to generate legit questions, we need to evaluate the correctness and relevance of the original responses, set criteria, and track learner performance in order to decide the difficulty of the question.

In order to create multiple-choice questions, we need to rank the original responses to get correct options and incorrect options. One challenge is that the original open-ended responses are graded with a quarter scale rather than binary scale. After analyzing the data, we came up with a set of ranking strategies:
Optimizing the length. The system will first calculate the average length of the original options. Then it calculates the length of each option candidate. Then we compare the two result as a score for length similarity.
Weighting the original scores. The weighted score is a combination of student score on quiz (60%) and their average score on all taken quizzes (40%) multiplied by their score on the particular question.
Separating correct and incorrect responses. Responses with weighted score of 0 will be considered as incorrect answers, others will be correct option candidates.
Calculate semantic similarity between responses and the original correct options. Some NLP techniques are used here:
1) TFIDF Vectorization is used to tokenize the answers.
2) A snowball stemmer is used to stem words.
3) A cosine similarity measure is used to compare similarity.
4) Create a corpus of correct and incorrect answers.
5) Initialize the vectorizers and remove stop words.
6) Finally we create a ranking list based on similarity to original correct options.
Calculate the final score of each response. We weight the semantic similarity score (60%) and the length similarity score (40%) and multiply the original weighted score to get the final score (which again automatically makes incorrect options score 0). Finally, we rank the responses according to their scores.
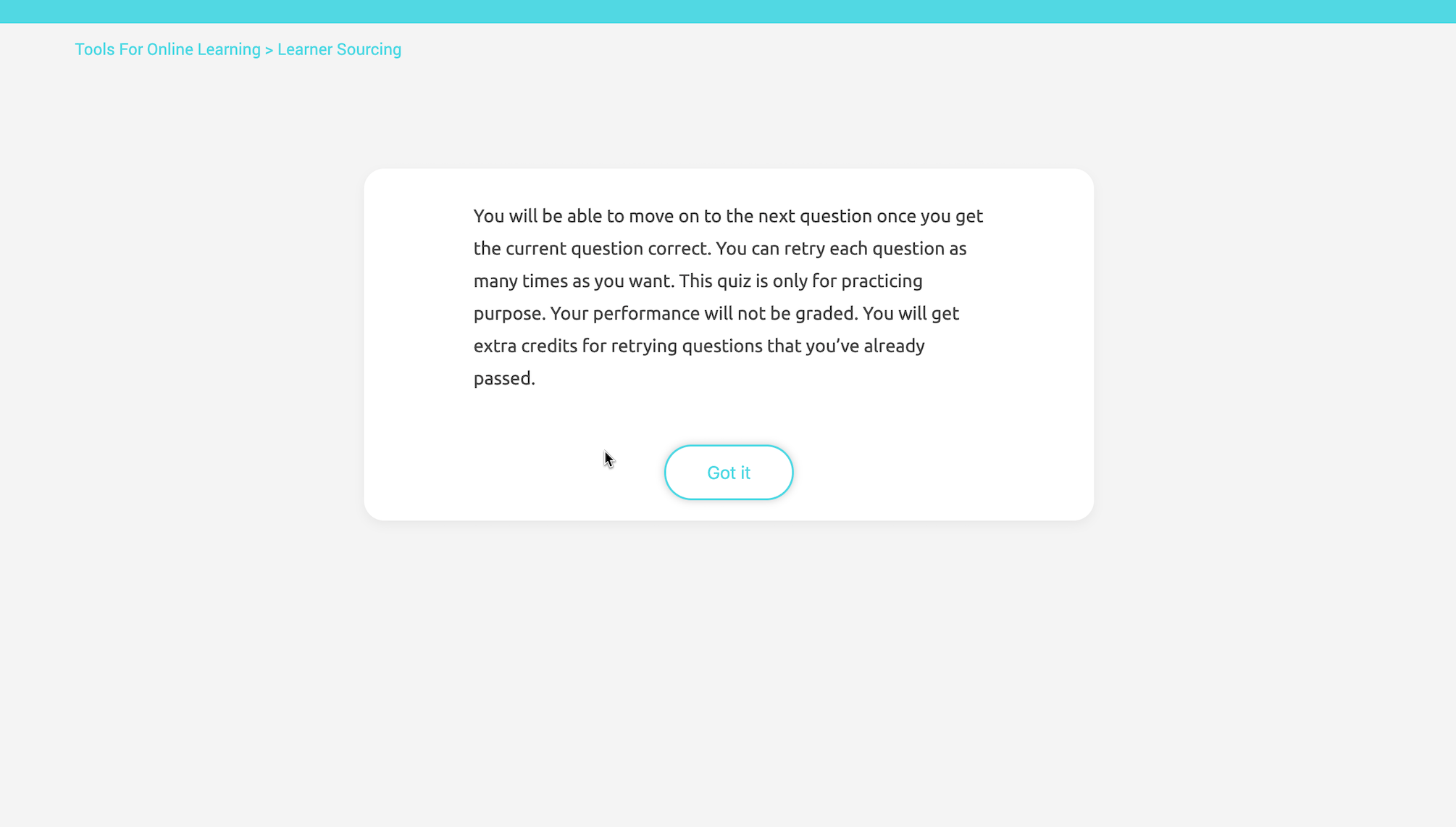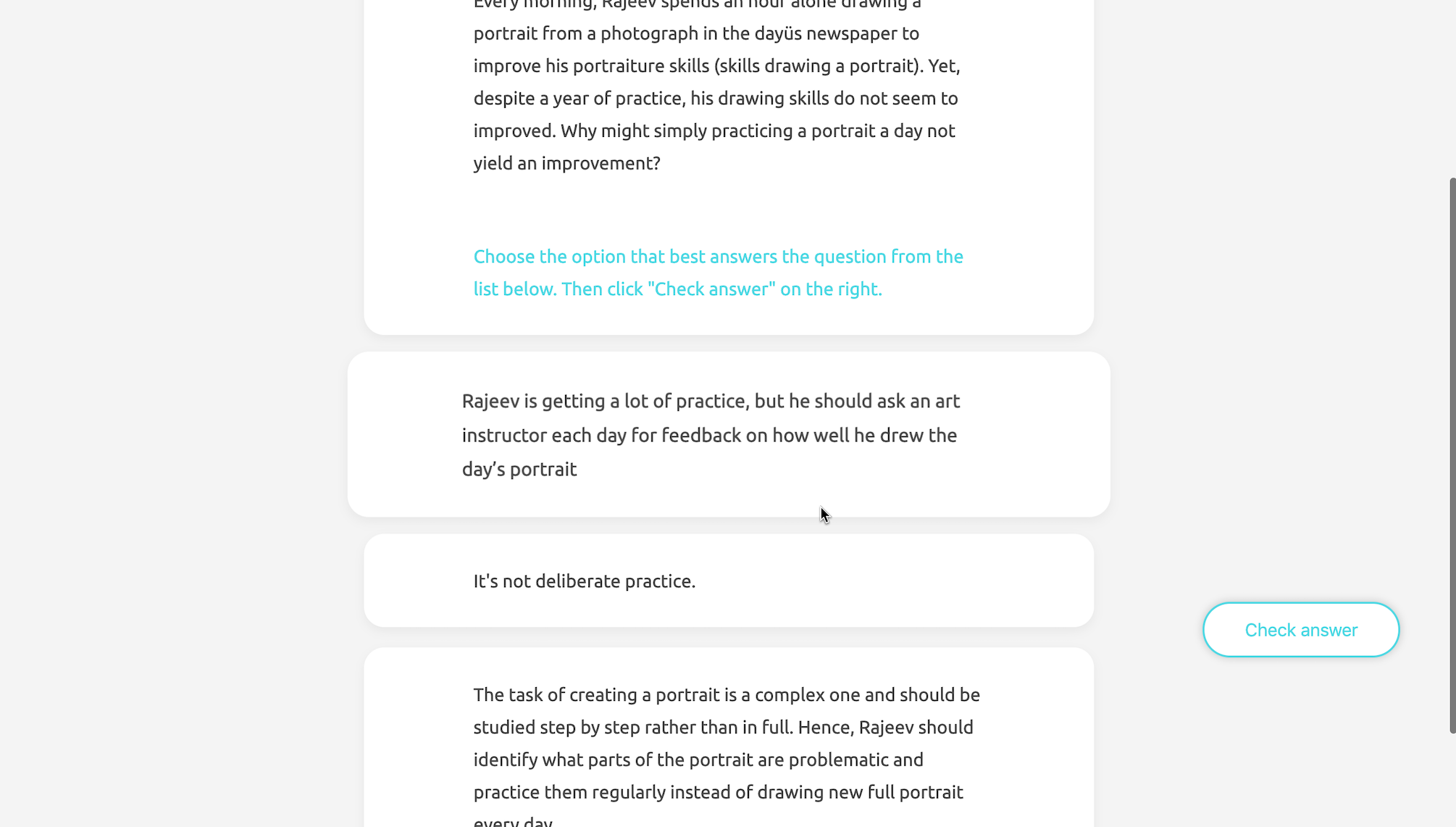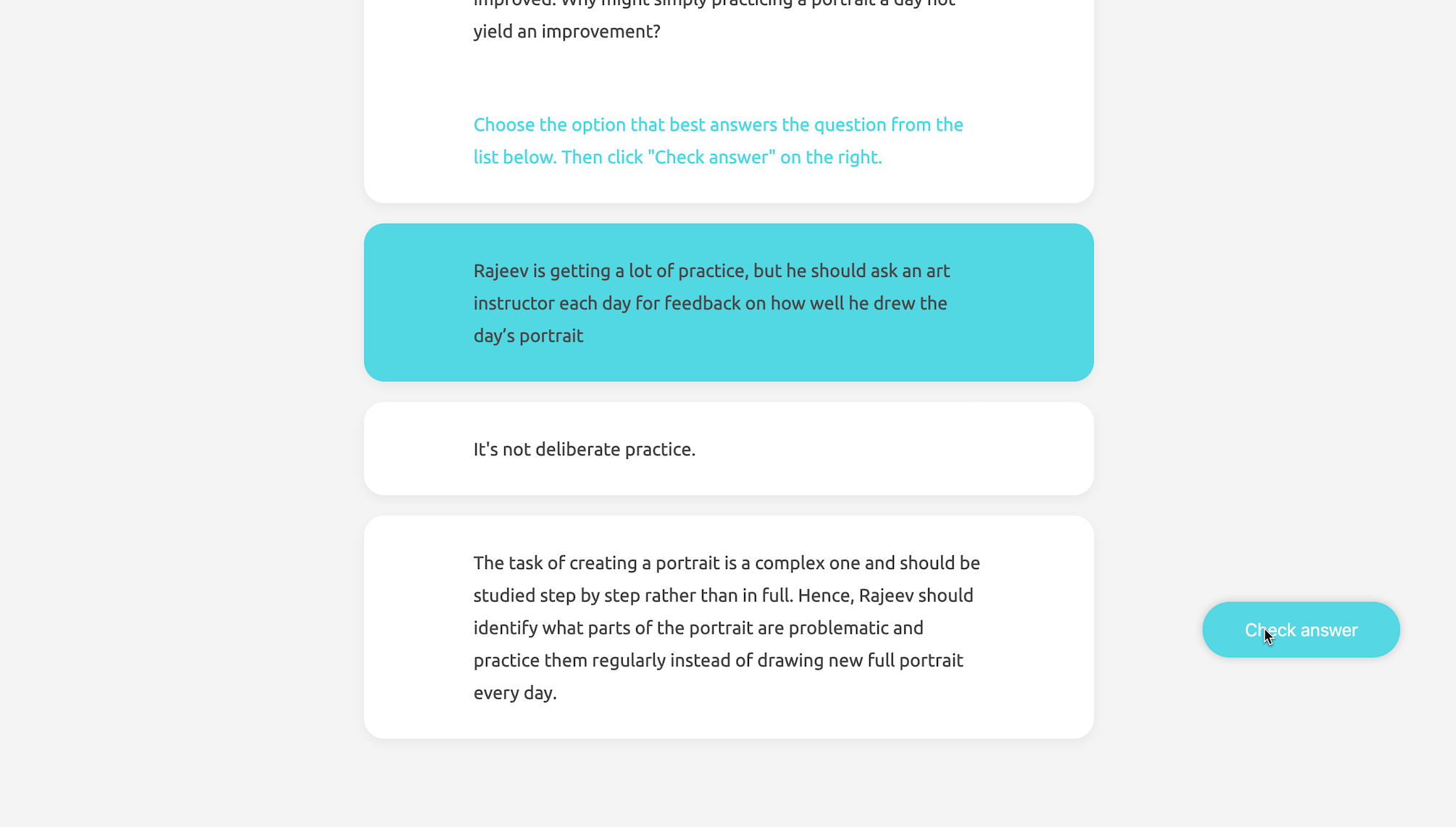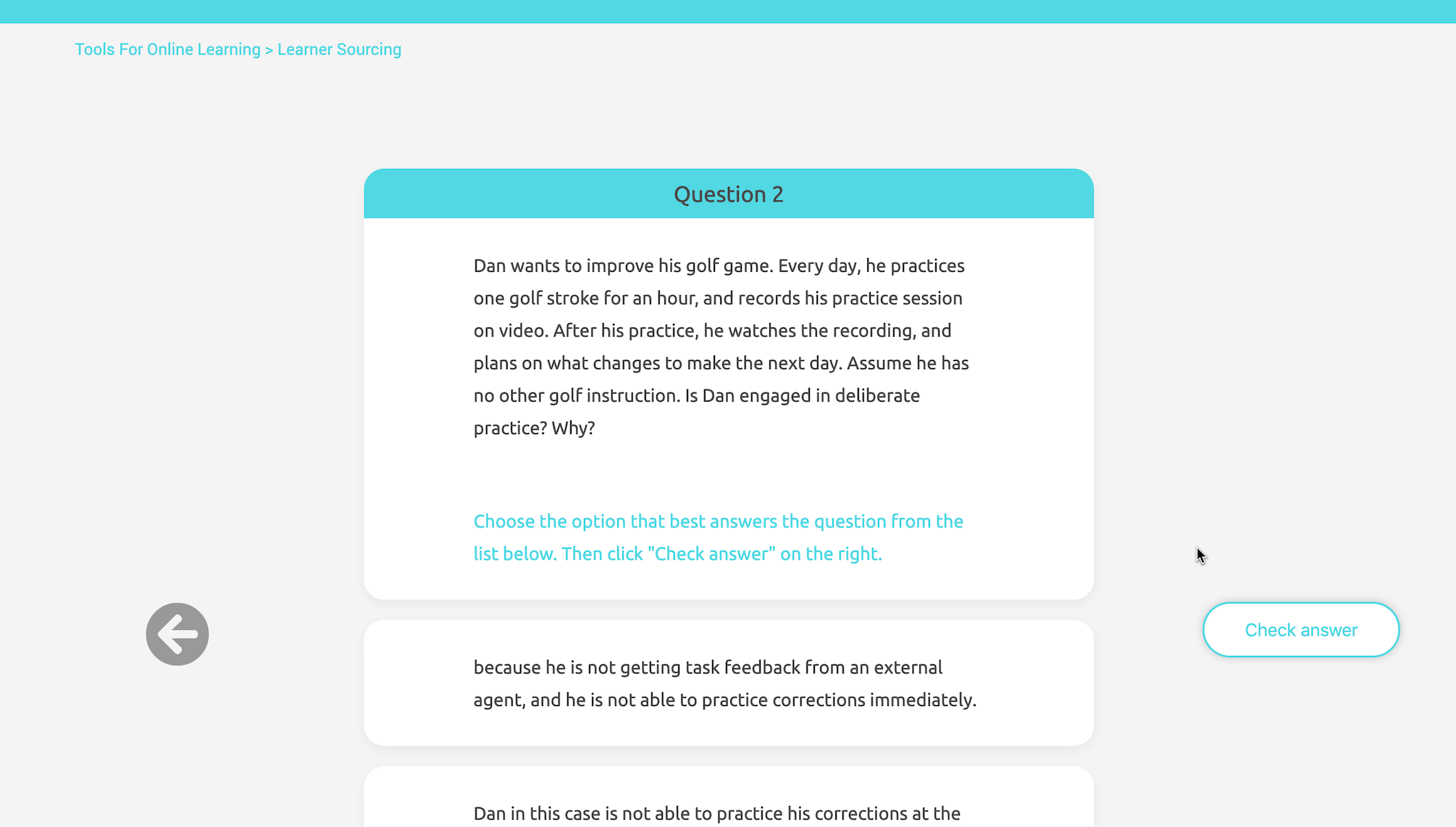
The quiz is designed as formative assessment without grading. Learners may move on to the next question once they get the correct answer, but they are encouraged to retry as many times as they want for learning purposes. Each time the question is refreshed, there will be different options generated real-time according to the ranking criteria. Due to the fact that learner-generated responses may be of low quality, there will be feedback after submission with the longest correct answer as a hint.
◇
REFLECTION
◇
Due to time limitation, we were not able to track learner performance the project. In the future, we plan to use the introduce adaptivity where the system will generate questions with different levels of difficulty according to how the learner performed. In order to do that, we need to further stratify the original responses. For example, if the question has one full-mark response and three 0 score response, it is deemed as easy; if it has one full-mark response and three 0.75 score responses, then it is deemed as a difficult one.